开发中的锁
先展示一个账本转账的例子
假设,账户的存在形式真的就是一个账本,这些账本都统一存放在文件架上。
银行柜员在给我们做转账时,要去文件架上把转出账本和转入账本都拿到手,然后做转账。
拿账本的规则:
- 文件架上恰好有转出账本和转入账本,那就同时拿走;
- 如果文件架上只有转出账本和转入账本之一,那这个柜员就先把文件架上有的账本拿到手,同时等着其他柜员把另外一个账本送回来;
- 转出账本和转入账本都没有,那这个柜员就等着两个账本都被送回来。
拿到这个业务场景就很容易写出以下的代码
1 | class Account{ |
我先锁住自己,再锁住target
乍一看好像很有道理
那么来考虑一下,现在有很多的并发场景,现在A要给B转账,同时B要给A转账
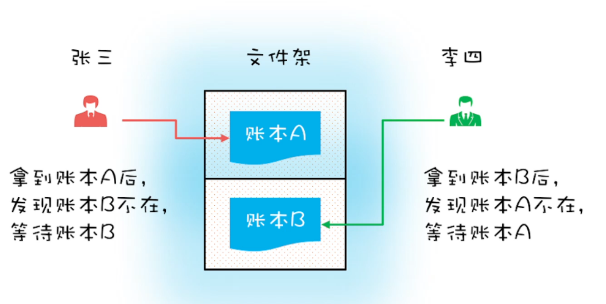
但是这个时候张三想从A转到B
李四想从B转到A
那么张三把A锁住的同时李四把B锁住
当他们互相想锁住B和A的时候发现,拿不到对方的锁,那么此时,A和B之间就产生了死锁
死锁
死锁产生的条件
- 互斥,共享资源X和Y只能被一个线程占用
- 占有且等待,线程T1已经取得共享资源X,在等待共享资源Y的时候,不释放共享资源X
- 不可抢占,其他线程不能强行抢占线程T1占有的资源
- 循环等待,线程T1等待线程T2占有的资源,线程T2等待线程T1占有的资源,就是循环等待
从中只要打破一个即可
但是1和3并不方便进行破坏,因为就是要解决并发场景下面的临界资源的获取
破坏循环等待
那么对于上面的例子,我们尝试破坏循环等待这个问题——这个问题比较好的解决办法就是让获取锁是有顺序的
1 | //转账 |
这个代码中不难发现将所有锁的获取按照顺序进行获取,通过一个判断大小,按照顺序获取锁,就可以避免循环依赖的问题。
破坏占有且等待
想要破坏这个条件,可以一次性申请所有资源,也就是同时申请到转出账户和转入账户的资源
1 | class Allocator{ |
该方法的缺点是容易产生瓶颈点,在申请资源的时候,比较容易产生。因为两个资源都需要进入临界区进行处理
这一条的核心是要能够主动释放它占有的资源,这一点synchronized是做不到的。
synchronized申请资源的时候,如果申请不到,线程直接进入阻塞状态了,而线程进入阻塞状态,啥都干不了,也释放不了线程已经占有的资源。
Java在语言层次没有解决这个问题,但是在SDK层面还是解决了,java.utl.concurrent下面提供的Lock是可以轻松解决这个问题的。
1 | //支持中断的API |
一些并发编程的套路
管程模型
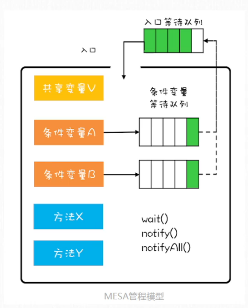
//这里还有待补充
MySQL的锁
锁的类型
- 全局锁
- 表级锁
- 表锁
- meta data lock (元数据锁)
- 行锁
- Record Lock(记录锁)
- Gap Lock(间隙锁)
- Next-Key Lock (next锁)
全局锁
MySQL提供了一个加全局读锁的方法,命令是Flush tables with read lock(FTWRL)。当你需要让整个库处于只读状态的时候,可以使用这个命令。
全局锁的典型使用场景是,做全库逻辑备份。
一般来说不会直接使用
主库在使用中如果直接使用,生产环境会直接拒绝写操作,导致生产线卡死
备库会接受bin log日志,也不能直接进行该操作,否则bin log日志的同步信息无法操作
那么全库备份一定要全局加锁么?
– 在可重复读隔离级别下开启一个事务。
官方自带的逻辑备份工具mysqldump,当使用参数-single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于MVCC的支持,这个过程中数据是可以正常更新的。 注意这里的隔离级别必须是可重复读的情况下,如果采用读已提交是不行的。这里涉及到MySQL的事务隔离级别,下面做一下补充。
表级锁
表锁
表锁的语法是lock tables..read/write。可以用unlock tables主动释放锁,也可以在客户端断开的时候自动释放。
举个例子,如果在某个线程A中执行lock tables t1read,t2 write;这个语句,则其他线程写t1、读写t2的语句都会被阻塞。
| X | S | |
|---|---|---|
| X | 不兼容 | 不兼容 |
| S | 不兼容 | 兼容 |
X:写锁
S:读锁
P.S. 一般日常开发不会直接使用这个命令
元数据锁
当对一个表做增删改查操作的时候,加MDL读锁;
当要对表做结构变更操作的时候,加MDL写锁。
不需要显式使用,在访问一个表的时候会被自动加上。MDL的作用是,保证读写的正确性。
| 会话1 | 会话2 | 会话3 | 会话4 |
|---|---|---|---|
| begin; | |||
| select * from user; | |||
| select * from user; | |||
| alter table user add f int null; |
|||
| select * from user; |
会话3在add操作的时候会阻塞,这里要注意在修改表结构的时候会自动进行元数据锁,直接锁住表
这里add操作直接阻塞,导致会话4在进行select操作的时候就阻塞了
行锁
Record Lock(记录锁)
仅仅把一条记录锁上
这里提供一个例子
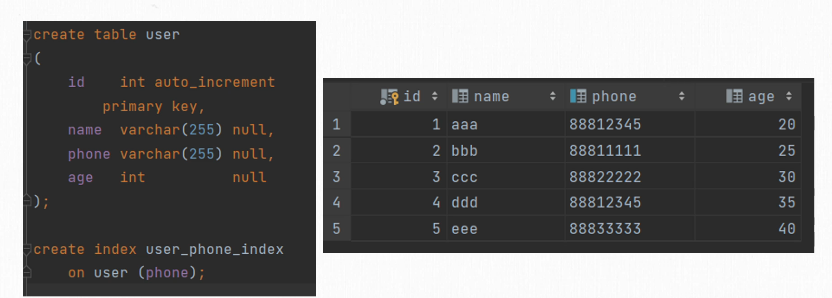
这里要注意到建立了一个phone的索引,并且其中记录1和记录4两个的phone都是一样的,所以不是唯一索引
案例一
| 会话1 | 会话2 |
|---|---|
| begin; | |
| update user set age = 20 where phone = ‘88812345’ and name = ‘aaa’; |
|
| begin; | |
| update user set age = 35 where phone = ‘88812345’ and name = ‘ddd’; |
|
| commit; | |
| commit; |
这里注意到aaa和ddd两个人的手机号相同
那么这个情况下,会发生阻塞么?
答案:
在会话2中更新操作的时候会阻塞
这里先放一张MySQL的索引结构
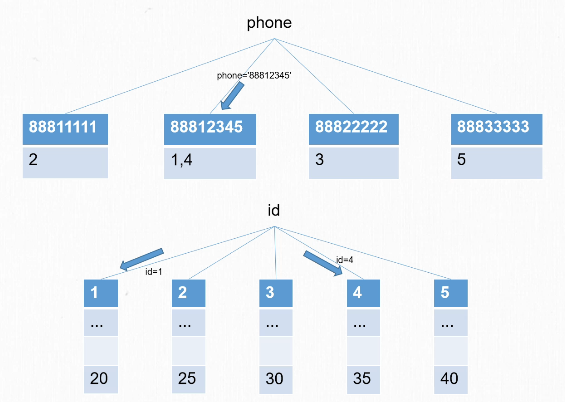
这里因为有索引phone,所以在处理的时候就会自动锁上有88812345的数据,会话1就会阻塞住1,4,
后面的会话2就没有办法对4进行处理,于是产生了阻塞
案例二
| 会话1 | 会话2 |
|---|---|
| begin; | |
| update user set age = age+1 where age = 20; |
|
| begin; | |
| update user set age = age+1 where age = 30; |
|
| commit; | |
| commit; |
这里用到的数据结构同上面一样
这里阻塞会更严重,因为age没有建立索引,所以在处理的时候没有办法直接获取到id,那么就会直接锁住全表,因为需要全部进行检索,这时候表的状态和全表锁住的状态很相似。
案例三
| 会话1 | 会话2 |
|---|---|
| begin; | |
| update user set age = age+1 where age = 20; |
|
| begin; | |
| update user set age = age+1 where id = 3; |
|
| commit; | |
| commit; |
情况同案例二
案例四
| 会话1 | 会话2 |
|---|---|
| begin; | |
| update user set age = age+1 where age = 20 limit 1; |
|
| begin; | |
| update user set age = age+1 where id = 3; |
|
| commit; | |
| commit; |
这里不会发生阻塞因为查到limit1的时候就不会继续往下查询了
案例五
| 会话1 | 会话2 |
|---|---|
| begin; | |
| update user set age = age+1 where age = 20 limit 1; |
|
| begin; | |
| update user set age = age+1 where age = 30; |
|
| commit; | |
| commit; |
这里会发生阻塞,虽然第一个已经把20找完了,但是age = 20的锁住了,后面要查询30的时候走age也要从头开始查询,那么这里的20那一条数据也会走,但是堵住了。
Gap Lock(间隙锁)
锁定一个范围,但是不包含记录本身
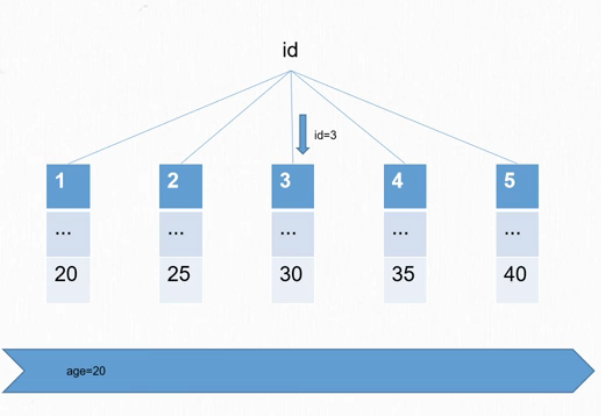
间隙锁就是在两个记录之间的锁
比如这里就是2025之间 2530之间······
上图中间隙锁总共有6种
主要为了读未提交的幻读问题
Next-Key Lock(记录锁+间隙锁)
//待补充
其他的一些问题
为什么要使用读写锁?
使用读写锁的主要目的是提高程序的并发性能和吞吐量。读写锁相较于互斥锁,在处理读取操作时具有更高的灵活性,因为它允许多个读取操作同时进行,而互斥锁则会将所有操作排队执行。以下是使用读写锁的一些优点:
提高并发性能:当多个线程同时进行读取操作时,读写锁可以避免互斥锁的串行执行,从而提高并发性能。
降低锁的粒度:读写锁可以降低锁的粒度,这意味着在执行读取操作时,不需要对整个资源进行加锁,可以只对资源的部分进行加锁,从而提高并发性能。
避免读到临时数据:读锁和写锁是互斥的,当一个线程正在进行写操作时,其他线程需要等待。这样可以确保读取操作不会读取到未提交的临时数据。
提高程序执行效率:通过使用读写锁,可以让多个读取操作并发执行,减少排队等待的时间,从而提高程序的执行效率。
使用读写锁的场景包括:文件读写操作(如从本地文件中读取数据到内存,或从网络中读取文件到本地)、数据库操作、共享数据结构等。Seata的默认隔离级别为什么是读未提交?
Seata 的默认隔离级别为读未提交(Read Uncommitted),主要是因为在分布式事务场景下,读未提交可以提供更高的性能和更快的响应速度。在读未提交隔离级别下,事务可以读取另一个未提交的事务所做出的修改,这样就不需要等待其他事务完成提交,从而降低了锁的竞争和事务的延迟。
此外,在分布式环境中,读未提交还可以有效地解决幻读问题。因为在分布式系统中,由于网络延迟和数据同步等原因,可能导致事务在读取数据时看不到其他事务的修改,使用读未提交隔离级别可以避免这种情况的发生。
需要注意的是,虽然读未提交隔离级别可以提供较高的性能和较快的响应速度,但它同时也可能导致脏读(Dirty Read)问题。脏读是指一个事务在读取数据时,看到了另一个未提交的事务所做出的修改,而这些修改可能会被回滚(Rollback),从而导致读取到的数据是脏数据。为了避免脏读问题,可以使用更高的隔离级别,如可重复读(Repeatable Read)或串行化(Serializable)。
总之,Seata 默认采用读未提交隔离级别,主要是为了在分布式事务场景下提供更高的性能和更快的响应速度,同时避免幻读问题。但在实际应用中,根据具体需求和场景,也可以选择其他隔离级别来满足不同需求。
事务隔离级别
待补充


